第2回Japan.R(#JapanR)を開催しました
2011/11/26に、第2回Japan.Rを開催しました!
Japan.Rは、全国のRコミュニティが合同で開催するイベントで
各地域コミュニティの紹介や情報交換、Rユーザ同士の交流等を目的として開催しています。
今年もR研究集会と合同で開催しました!
発表資料
Japan.RとR研究集会で3つほど発表させてもらったので、 その資料を載せておきます。
Japan r2 opening
View more presentations from yokkuns
Japan r2 tokyor
View more presentations from yokkuns
Japan r2 lt_yokkuns
View more presentations from yokkuns
反省など
- 今年は、主催らしい事が何も出来ず、@holidayworkingさんと@dichikaさんが中心となって進めてくださいました。本当にありがとうございました!
- 実質、オープニングの挨拶とR研究集会での発表くらいでした。。。
- ブースセッションでは、一緒に担当して下さった@millionsmileさんに大変お世話になりました。ありがとうございました!
- @millionsmileさんが中心となって、複雑ネットワークについて参加者の方々といろいろな議論ができ、とても勉強になりました
- LT大会では、@yuchimiri さんにドラを叩いてもらい、大変盛り上がりました!ありがとうございました!
- 今回、Japan.Rのオープニング曲を、@shumusixさんに作っていただきました!ありがとうございました!
- 諸事情で、オープニングなのに、最後に流す事になってしまいましたが・・・
- 来年は、もうちょっと早い時期から動いて、直前で忙しくなっても周りに迷惑をかけないようなスケジュールで進めて行きたいと思います。
第15回 データマイニング+WEB @東京 ( #TokyoWebmining 15th)−統計・ビジネス活用 祭り−に参加してきました。
Opening Talk
「統計カリキュラム 第1回−一般化線形モデル−」 (講師: @isseing333さん) (発表30分 + 議論30分)
Tokyo webmining統計学部 第1回v2
View more presentations from Issei Kurahashi
「医療分野におけるデータマイニングを始める前に知っておきたいこと (講師: @dichika )(発表20分 + 議論20分)
- 対策のインパクト
- どの層を狙っているか明確に
- 木を見て森を見ずになっていないか
- 一足飛びのロジックになっていないか
- どの層を狙っているか明確に
- 手法の選択
- 結果を見せる相手は誰か
- 重回帰分析から説明する必要あり
- ランダムフォレスととか無理
- 説明しやすい手法
- 相手が馴染んでいるスタイルで
- 医学分野 : 実験計画+調査+説明モデル
- 線形モデル、決定木モデル
- 結果を見せる相手は誰か
「複雑ネットワークとデータマイニング 徹底入門」 (講師: @milionsmile) (発表30分 + 議論30分)
Tokyo webmining 複雑ネットワークとデータマイニング
View more presentations from Hiroko Onari
「エンジニア向けマーケティングリサーチ入門」 (講師: @tetsuroitoさん) (発表20分 + 議論20分)
発表資料 : http://prezi.com/_njjlvrp-dri/116-tokyo-wemining-marketing-research-for-engeenier/
- マーケティングリサーチ
- 顧客のニーズ・ウォンツをリサーチすること
- マーケティングリサーチの心構え
- 誰が何をするための事を知りたいのか
- 何が分かると自分たちはうれしいのか
- 分析手法
- 因子分析
- クラスター分析
- コレスポンデンス分析
- コンジョイント分析
- ターゲットとする顧客のニーズの優先順位を明らかにし、個々のニーズが購買の意思決定に及ぼす影響が大きいか把握出来る
「2chのイカ娘スレッドを時系列分析してみた」 (講師: @gepuro ) (発表20分+ 議論20分)
2ch
View more presentations from gepuro
第18回R勉強会@東京(#TokyoR)を開催しました!
2011/10/22に、第18回R勉強会@東京(#TokyoR)を開催しました!
以下、内容です。
資料はアップされ次第、更新します!
@aad34210 「はじめてのR 」(20分)
概要 : Tokyo.Rでは高度な手法が紹介されていますが、いざ使いたくてもRは初めてなのでコードがよくわからない…といった初心者の方に向けてお話します。
Tokyo r18
View more presentations from aad34210
@dichika XLConnectで快適なエクセルライフのご提案 (15分)
概要 : XLConnectパッケージであなたのエクセルライフを豊かにします
Tokyor18
View more presentations from dichika
@takemikami 「Rによるデータサイエンス第13章「樹木モデル」」(30分)
概要 : テキスト「Rによるデータサイエンス」に沿ってRでの樹木モデルの扱い方を解説します。
Rによるデータサイエンス13「樹木モデル」
View more presentations from Takeshi Mikami
@horihorio 「Rで学ぶ現代ポートフォリオ理論」 (30分)
概要 : 「全部の卵を同じカゴに入れるな」との格言もある分散投資、これはなぜ良いのか?を紹介します。
Portfolio tokyo r#18
View more presentations from horihorio
atgmacontnd 部分的最小二乗法(30分)
@kenchan0130_aki 「最適化アレ コレ ソレ」(20分)
概要 : Rには様々な最適化関数が用意されています。色々使ってみよう。
Tokyo r 10_12
View more presentations from Tadayuki Onishi
@holidayworking 「RHadoopの紹介」(30分)
概要 : RからHadoopを操作することができるパッケージの紹介
@Hiro_macchan Rで計量経済(操作変数を使ったバイアス調整)(10分)
概要 : 計量経済領域でよく用いられる操作変数を使ったバイアス調整について、Rを使った利用方法を紹介したいと思います。
ネットワーク分析 - ベイジアン・ネットワーク
ベイジアンネットワークとは
事象間の連関を確率的な仮定として、有向グラフを用いて表す方法。
ネットワーク構造は、DAGでなければならないという制約がある。(原因と結果が循環的な構造になってしまうのを避けるため)
ベイジアン・ネットワークをデータ分析に応用すると、変数間の連関を有効グラフで表す事が出来る。
ベイジアン・ネットワークにおける有向辺の有無を決める基準には、確率的な「独立」が用いられる。

このとき、
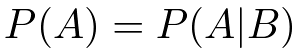
なので、Aの確率はBの影響を受けない。
このように2つの変数が独立、もしくはそれにちかければ、それらの間に連関は無いと考え、それらの変数を表すノード間にエッジは張られない事になる。
ベイジアン・ネットワークの例
データは、ネットワーク分析 (Rで学ぶデータサイエンス 8)に出てくる「ハイテク企業の管理職21人の社会ネットワーク」。
- ハイテク企業の管理職データ
| Age | Tenure | Dpt. | Level | advice | friend | re |
| 33 | 9.333 | D4 | L3 | 13 | 8 | 0 |
| 42 | 19.583 | D4 | L2 | 18 | 10 | 3 |
| 40 | 12.750 | D2 | L3 | 5 | 5 | 0 |
| 33 | 7.500 | D4 | L3 | 8 | 5 | 0 |
| 32 | 3.333 | D2 | L3 | 5 | 6 | 0 |
| 59 | 28.000 | D1 | L3 | 10 | 2 | 0 |
| 55 | 30.000 | D0 | L1 | 13 | 3 | 4 |
| 34 | 11.333 | D1 | L3 | 10 | 5 | 0 |
| 62 | 5.417 | D2 | L3 | 4 | 6 | 0 |
| 37 | 9.250 | D3 | L3 | 9 | 1 | 0 |
| 46 | 27.000 | D3 | L3 | 11 | 6 | 0 |
| 34 | 8.917 | D1 | L3 | 7 | 8 | 0 |
| 48 | 0.250 | D2 | L3 | 4 | 1 | 0 |
| 43 | 10.417 | D2 | L2 | 10 | 5 | 7 |
| 40 | 8.417 | D2 | L3 | 4 | 4 | 0 |
| 27 | 4.667 | D4 | L3 | 8 | 4 | 0 |
| 30 | 12.417 | D1 | L3 | 9 | 6 | 0 |
| 33 | 9.083 | D3 | L2 | 15 | 4 | 2 |
| 32 | 4.833 | D2 | L3 | 4 | 5 | 0 |
| 38 | 11.667 | D2 | L3 | 8 | 3 | 0 |
| 36 | 12.500 | D1 | L2 | 15 | 5 | 4 |
インストールと読み込み
install.packages("deal") library(deal)
データの読み込みとネットワークの初期化
データを読み込んで、networkオブジェクトを生成する
ht <- read.table("high_tech.dat", header=T) ht.nw <- network(ht) plot(ht.nw)
この状態では、まだネットワークは、エッジを持たない空グラフ。
事前分布と事後分布の計算
事前分布と事後分布を計算する。この時、明らかに影響がない変数間のエッジを除外するためのリストを作っておく。
- 例 : 年齢は他の変数から影響を受ける可能性はないので、他のノードから年齢のノードにはエッジを張らないなど
# 事前分布の計算 ht.prior <- jointprior(ht.nw) # 除外リスト mybanlist <- matrix(c( 2,1, 3,1, 4,1, 5,1, 6,1, 7,1, 3,2, 4,2, 5,2, 6,2, 7,2, 3,4, 4,3), ncol = 2, byrow = TRUE) banlist(ht.nw) <- mybanlist # 事後分布の計算 ht.nw <- learn(ht.nw, ht, ht.prior)$nw # ネットワークスコアが最適になるネットワークを探索 ht.search <- autosearch(ht.nw, ht, ht.prior, trace = TRUE)
結果
> ht.search <- autosearch(ht.nw, ht, ht.prior, trace = TRUE) [Autosearch (1) -352.149 [Age][Tenure][Dpt.][Level][advice][friend][report|Level] (2) -349.392 [Age][Tenure][Dpt.][Level][advice|Level][friend][report|Level] (3) -347.2447 [Age][Tenure][Dpt.][Level][advice|Dpt.:Level][friend][report|Level] (4) -345.6413 [Age][Tenure|Age][Dpt.][Level][advice|Dpt.:Level][friend][report|Level] (5) -344.7486 [Age][Tenure|Age][Dpt.][Level][advice|Dpt.:Level:report][friend][report|Level] (6) -344.2724 [Age][Tenure|Age][Dpt.][Level][advice|Dpt.:Level:friend:report][friend][report|Level] (7) -343.9905 [Age][Tenure|Age][Dpt.][Level][advice|Tenure:Dpt.:Level:friend:report][friend][report|Level] (8) -343.9629 [Age][Tenure|Age][Dpt.][Level][advice|Tenure:Dpt.:Level:friend:report][friend|Dpt.][report|Level] (9) -343.1464 [Age][Tenure|Age][Dpt.][Level][advice|Tenure:Dpt.:Level:friend:report][friend|Tenure:Dpt.][report|Level] (10) -342.7576 [Age][Tenure|Age][Dpt.][Level][advice|Tenure:Dpt.:Level:report][friend|Tenure:Dpt.:advice][report|Level] Total 1.875 add 1.127 rem 0.263 turn 0.082 sort 0.047 choose 0.036 rest 0.32 ]
描画
plot(ht.nw)
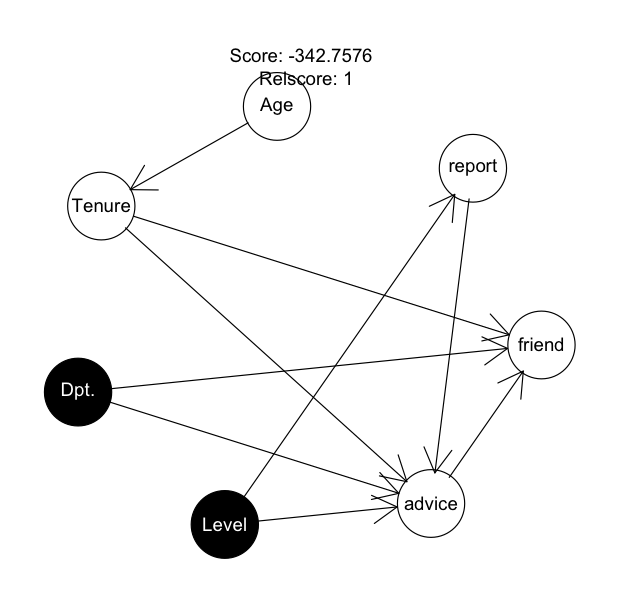
図に出力されている、-342.7576は、以下のネットワークスコアの対数で、ベイジアン・ネットワークがデータと合致する程度を表している
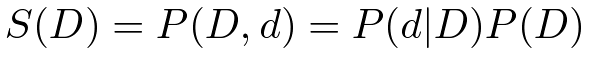
第17回R勉強会@東京(#TokyoR)を開催しました!
第17回R勉強会@東京(#TokyoR)を開催しました!
以下、メモです。
発表枠
@teramonagi: Rによるデータサイエンス第12章「時系列」 (30分程度)
概要 : テキスト「Rによるデータサイエンス」に沿ってRでの時系列の扱い方を解説します。
Rによるデータサイエンス:12章「時系列」
View more presentations from teramonagi
- メモ
- ラグ処理 : lag関数
- 差分処理 : diff関数
- 時系列で使う統計量
- 平均
- 自己共分散
- 自己相関
- 自己相関のplot
- act(UKgas, ci=0.9)
- ci : 信頼区間
- 青の点線を超えていると、自己相関があると言って良いということ
- 自己相関をなくす処理 = ラグ処理
- 相互共分散、相互相関ccf
- スペクトル分析 = 周期性の解析
- 基本的な概念 : 周波数で物事を考える。波の重ね合わせで物を見る
- ピリオドグラム : spec.pgram(y, log="no")
- expand.grid(p,d,q) で全組み合わせを計算してくれる
- GARCHモデル
- Not 時系列自体 But 分散 のモデル
- 成分の分解
- 観測値 = トレンド + 周期変動 + 残差
@holidayworking Rで解く最適化問題 – 線型計画問題編 – (30分)
概要 : 「最適化法」を参考書にして最適化問題をRでやってみようと思います。第一段は最適化問題の基礎と線型計画問題について説明します。
Rで解く最適化問題 線型計画問題編
View more presentations from Hidekazu Tanaka
数式が多かったので、メモが間に合わず・・・
@kos59125: 近似ベイズ計算でカジュアルなベイズ推定(20–30分)
概要 : 近似ベイズ計算を用いると複雑なモデルでも簡単にベイズ推定が行えます。その手法と実例を紹介します。
近似ベイズ計算によるベイズ推定
View more presentations from Kosei Abe
@yokkuns: Rで学ぶ傾向スコア解析入門 (30分)
概要: 因果推論とか傾向スコア解析とかその辺の話題についてやってみたいと思います。
参考文献: 調査観察データの統計科学
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
View more presentations from yokkuns
@mangantempy: サーバ異常検知入門 (30分)
概要 :サーバーの負荷を統計的に分析してみようと思います。実際の観測値を時系列モデルに当てはめてグラフに描画する方法などを解説します。
サーバ異常検知入門
View more presentations from mangantempy
- アラートがあがってからじゃ、大体遅い => 監視して、統計的手法で事前に検知出来ないか?
- ディスク容量が、あと何分であふれるかを予測
- 日付が、2011-09-24(今日)!
@yuuukioii Rによる計量経済学入門(20分)
概要 : ロジット分析を計量経済学的観点からやってみたいと思います。
Rて計量経済学入門#tokyo.r.17
View more presentations from yuuukioii
LT枠
@dichika: TokyoR等の軌跡(5分)
概要: 私たちのこれからを考えるためにも今までどのような発表があったのか整理したいと思います。
Tokyor17
View more presentations from dichika
@tsutatsuta: Rで富士山を描いてみた(5-10分)
概要: x, y, z 軸で表せるデータ(3次元のベクトル)を,image,scatterplot3d,persp関数などを用いてグラフ化する方法について.せっかくなので富士山をグラフ化してみます.
3次元のデータをグラフにする(Tokyo.R#17)
View more presentations from Takumi Tsutaya
@wakuteka: Tsukuba.Rの軌跡(5分)
Tsukuba.Rが、メンバーの就職で最近出来ていないので、近い人一緒にやりましょう!
飛び入りLT
@gepuro: ログ解析
クラスタリングしたよ!
第16回R勉強会@東京(#TokyoR)を開催しました!
第16回R勉強会@東京(Tokyo.R#16)を開催しました!
内容
@sleipnir002:Rで学ぶデータサイエンス5パターン認識 8,9k-近傍法、学習ベクトル量子化
概要:教科書の内容にそって、上記のアルゴリズムの勉強をします。
パターン認識 08 09 k-近傍法 lvq
View more presentations from sleipnir002
@Hiro_macchan : Rを用いた地理的情報解析
概要:Rを用いた地理的情報の解析について、RにもGISにも詳しくない人間ががんばった経緯を発表できればと思います。
@ito_yan : Rで実験計画法
概要: 一元配置から、基本的な直交実験までご紹介できればと考えています。僕と勉強会に出て、実験計画法使いになってよ!
@tyatsuta: DICEWARS by R
概要: DICEWARSをプレイした上でお聞きいただければ幸いです。
Tokyo r16
View more presentations from YATSUTA Toshihisa
@wdkz: Rで大規模データ解析
概要:Rで大規模なデータを扱ってみます。SAS9.3には負けないぞ
@dichika: シリーズRで可視化#2 インフォグラフはじめました
概要:インフォグラフをRで実現するにはどうしたらよいかこれから調べようと思います
Tokyor16
View more presentations from dichika
@yokkuns: 異常行動検出入門 – 行動データ時系列のデータマイニング –
概要: 一連の行動データを単位とした時系列を対象とした異常検知。行動データ時系列から行動パターンを学習し、なりすましや障害などの異常を検出する方法論を紹介したいと思います。
異常行動検出入門 – 行動データ時系列のデータマイニング –
View more presentations from yokkuns

反省
- 時間管理を全然やっていなくて、後半かなり時間がなくなってしまったので、今後ちゃんとやりたい
- 資料作成を前日の夜から始める癖をなおしたい
次回
次回は、9/24(土)に開催します!
まだ、LT募集していますので、よろしくお願いします!
第13回 データマイニング+WEB @東京 ( #TokyoWebmining 13th)−Mahout・大規模解析・ビジネス展開 祭り− に参加してきた
第13回 データマイニング+WEB @東京で、異常検知について発表してきました。
発表資料は以下です。
時系列分析による異常検知入門
View more presentations from yokkuns
今回、時間がなくて実装まで出来なかったので、次回か次次回のTokyo.Rでは実装してみたいと思います。