RでTwitter
最近、何故かRという統計・解析用のプログラミング言語を使っているんですが、何となく、CRAN(perlのCPANみたいなやつ)を眺めてたら、twitteRというパッケージを発見した。
インストールと読み込み
> install.packages("twitteR") > library("twitteR")
認証がいらないやつ
public_timeline
> head( publicTimeline() ) [[1]] [1] "DeadEmptyHeart: @LeleClearwater_ Are u jealous or something?" [[2]] [1] "encopan: @mobaweb なにこのあいこんかわえええええ!" [[3]] [1] "ZoO_CreW_HeF: RT @LiQMYJUiCEBOx: I need a boyfriend for the month! Good luck w/ that lOl" [[4]] [1] "hsergiocarvalho: @Dall_ Aercio presidente, Ciro vice, o DEM dançou com o caso Arruda" [[5]] [1] "JustinJay_: @zoebritton how much does it cost to watch?" [[6]] [1] "marjanwelman: @soldanosoldier Cuuuuute!"
user_timeline
> head( userTimeline("yokkuns") ) [[1]] [1] "yokkuns: おぉ、これは便利。もうbot作れてしまうな" [[2]] [1] "yokkuns: あ、ちゃんとマニュアルあった" [[3]] [1] "yokkuns: statusはどうやって取るんだろう" [[4]] [1] "yokkuns: 出来た" [[5]] [1] "yokkuns: テスト" [[6]] [1] "yokkuns: sess <- initSession('myUser', 'myPass') ns <- updateStatus('this is my new status message', sess)"
認証が必要なやつ
初期化
> yokkuns <- initSession("yokkuns","********")
friends_timeline
一応IDは、伏せました。
> head( friendsTimeline(yokkuns) ) [[1]] [1] "xxxxxx: 二日酔いけてーいwあぁかえりてぇ" [[2]] [1] "xxxxxx: 自分と大して身長の変わらない少年がランドセルしょってた。ウケる。" [[3]] [1] "xxxxxx: ワンストップ・サービスって取り組みは評価する。普及するには難しいけど。そうなればこの公共人生相談所はハローライフとかに改名して生活再建を謳うのが良い。もはや仕事を斡旋してどうこうなるレベルではないような気がするんだ。" [[4]] [1] "xxxxxx: ポッポは、年収と月収の違いは理解できてるのかなぁ?年だよぉ。 QT @xxxxxx 子ども手当、年収2000万円上限 政府調整、与党に引き下げ案 NIKKEI NET http://bit.ly/7a8A6T" [[5]] [1] "xxxxxx: おはようございます。今日はメトロ遅延していないようで安心しました。" [[6]] [1] "xxxxxx: 寒い。寒すぎる。"
mentions
一応IDは、伏せました。
> head( mentions(yokkuns) ) [[1]] [1] "xxxxx: @yokkuns \"R\"に反応。" [[2]] [1] "xxxxx: @yokkuns おはっす!寒いですねーー!" [[3]] [1] "xxxxx: @yokkuns コーヒー 60円了解しました。先月の食費は、3980円、今月は今日までに760円です。" [[4]] [1] "xxxxx: @yokkuns だめ!!!!" [[5]] [1] "xxxxx: @yokkuns 歌詞探してねw" [[6]] [1] "xxxxx: @yokkuns 特急料金を…(ry 歌詞がない…。"
statusクラス
返ってくる結果は、statusクラスのオブジェクトのリストになっていて、statusクラスは以下のようなメソッドが用意されている。
show text favorited replyToSN created truncated replyToSID id replyToUID statusSource screenName
yokkunsで試してみると
> yokkuns_status <- userTimeline("yokkuns") > yokkuns_status[[1]] [1] "yokkuns: 3歳児って、もうPC使いこなせるんだなぁ。。。" > class(yokkuns_status[[1]])[1] "status" attr(,"package") [1] "twitteR" > show(yokkuns_status[[1]]) [1] "yokkuns: 3歳児って、もうPC使いこなせるんだなぁ。。。" > text(yokkuns_status[[1]]) [1] "3歳児って、もうPC使いこなせるんだなぁ。。。" > favorited(yokkuns_status[[1]]) [1] FALSE > replyToSN(yokkuns_status[[1]]) character(0) > created(yokkuns_status[[1]]) [1] "Sun Dec 20 02:21:33 +0000 2009" > truncated(yokkuns_status[[1]]) [1] FALSE > replyToSID(yokkuns_status[[1]]) numeric(0) > id(yokkuns_status[[1]]) [1] 6847297103 > replyToUID(yokkuns_status[[1]]) numeric(0) > statusSource(yokkuns_status[[1]]) [1] "<a href=\"http://d.hatena.ne.jp/lynmock/20071107/p2\" rel=\"nofollow\">P3:PeraPeraPrv</a>" > screenName(yokkuns_status[[1]]) [1] "yokkuns"
kakeibotで試す
以下のリプライに対してRCaBoChaを使って、何にいくら使ったというのを解析してみる。
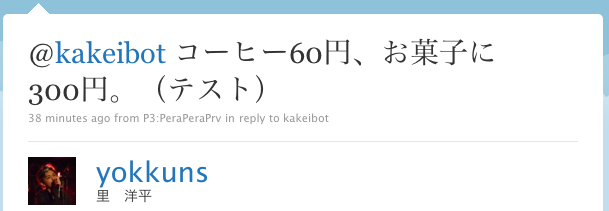
この場合、単純に形態素解析して順番に取れば済みそうな話ではあるが、勉強のためということで。。。
- kakeibotとして接続
> kakeibot <- initSession("kakeibot", "********")
- リプライを取得
> kakeibot_mentions <- mentions(kakeibot) > kakeibot_mentions[[1]] [1] "yokkuns: @kakeibot コーヒー60円、お菓子に300円。(テスト)"
- 本文をRCaBoChaにかける。
この時、そのままだと上手くいかなかったので、「〜に○○円使った」となるように加工してみた。
> text(kakeibot_mentions[[1]]) [1] "@kakeibot コーヒー60円、お菓子に300円。(テスト)" > str <- text(kakeibot_mentions[[1]]) > (data <- subset(RCaBoCha(gsub("([0-9]+)円", "に\\1円使った。", gsub("@kakeibot", "", str))), POS == "名詞" & Term1!= "円")) FROMAT_TREE = コーヒーに---D <MONEY>60円</MONEY>-D 使った。、-------D お菓子にに---D | <MONEY>300円</MONEY>-D | 使った。。-D (テスト) EOS Term1 Term2 POS D1 D2 1 コーヒー コーヒー 名詞 1 2 3 60 * 名詞 2 2 9 お菓子 お菓子 名詞 4 5 12 300 * 名詞 5 5 19 テスト テスト 名詞 7 -1
- 整形
D1 == D2になるようなデータフレームを作成。
> (expense <- subset(merge(data, data, by.x="D1", by.y="D2"), Term1.x != Term1.y)) D1 Term1.x Term2.x POS.x D2 Term1.y Term2.y POS.y D1.1 1 2 60 * 名詞 2 コーヒー コーヒー 名詞 1 3 5 300 * 名詞 5 お菓子 お菓子 名詞 4
こんな感じで「金額 - もの」の形にして、「もの」を分類器にかけてカテゴリを選択すれば、複数の登録も可能になりそうだ。