kmeansで楽できる(かもしれない)パッケージを作った
k-means法は、非階層的クラスタリングの代表的な手法ですごく便利ですが、使って行く上で、以下の2つが問題になってきます。
- 初期値がランダムなので、結果がぶれる
- 最適なクラスタ数が分からない
この2つの弱点に対して拡張版や手法が提案されていますが、すごくシンプルな方法で解決するパッケージを作ってみました。
その名もykmeansパッケージ・・・!
- http://cran.r-project.org/web/packages/ykmeans/index.html
- ※改良とか拡張とかしてるわけではないので、kmeans2とか付けるのは自重した
このパッケージは、上記の二つの問題に対して、以下のアプローチで対応しています。
N回実行して一番多く分類されたクラスタを採用する
例えば、あるデータで100回実行して、そのクラスタの平均値をプロットすると、↓のようにクラスタの中心が結構ぶれます。
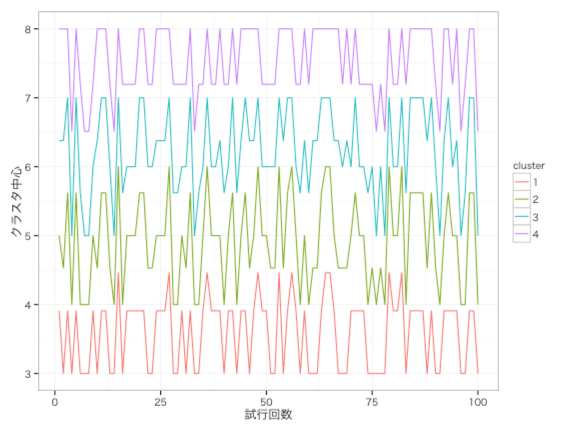
クラスタの中心がずれると、当然分類されるクラスタが変わってしまうデータが出てきます。
なので、1回だけの実行では中々不安になってきます。
そこで、このパッケージでは、
「とりあえず100回くらい実行すれば安定するだろう」
という仮定のもとに、100回実行して、一番多く分類されたクラスタを採用しています。
(※回数は指定出来ます)
任意の変数のクラスタ内分散の平均値が小さくなるクラスタ数を採用する
自分がクラスタリングを使うときは、目的にもよりますが、ある程度クラスタ数の範囲は事前に決めています。
多すぎると解釈や説明がつらくなってくるので、3〜6、多くて10くらいに設定するのが多いです。
また、「クラスタリングして終わり」ではなく、各クラスタのKPIを比較するなど別の分析があります。
なので、クラスタ内で、見ようと思っているKPIが出来るだけ近い方が都合が良いです。
そこで、このパッケージでは、
「見ようと思っている変数が、クラスタ内でなるべく散らばらないクラスタ数」
を採用しています。
使い方
- ykmeans (x, variable.names, target.name, k.list, n)
| x | データフレーム |
| variable.names | クラスタリングの時の使う説明変数名 |
| target.name | クラスタ間で比較しようと思っている変数名 |
| k.list | クラスタ数候補 |
| n | 試行回数 |
実行例
- 使うデータ
library(ykmeans) head(actData)
## y x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 ## 1 17030 7 3 4 3 3 3 3 2 3 3 1 2 3 2 2 2 2 ## 2 1360 5 3 4 4 2 4 3 0 4 2 2 2 2 1 2 2 1 ## 3 1360 7 4 3 4 2 4 3 3 2 3 2 2 2 2 2 2 1 ## 4 100 5 2 3 2 3 1 2 3 2 1 2 1 1 2 1 0 1 ## 5 320 4 3 3 2 3 1 2 2 1 1 2 2 1 1 2 1 0 ## 6 2820 7 4 3 4 3 4 3 3 2 3 3 1 2 2 2 1 1
- ykmeans関数の実行
ykm <- ykmeans(actData, paste0("x", 1:17), "y", 3:6) table(ykm$cluster)
## ## 1 2 3 4 5 ## 140 92 16 148 104
-
- このデータでは、3〜6個のクラスタ数を試して「5」が採用されています。