ビジネス活用事例で学ぶ データサイエンス入門 という本を書きました (その1)
ビジネス活用事例で学ぶ データサイエンス入門 という本を執筆しました!
まだ発売前ですが、少しだけ中身を紹介してみたいと思います。
興味がありましたら、是非ご予約ください!
はじめに
(※出版社を配慮し、原文そのままではないです)
日々、データ分析の実務をしていると、次のような言葉をよく聞きます。
- A. 膨大な費用を使ってデータを収集し解析してもらったけど、期待したほどの爆発的な効果はでてこないなぁ。
- B. 分析部署から詳細な報告を送ってくれるのですが、やたら難しい報告書で、とても読めません。
- C. 一応データは残していますが、忙しくて分析しきれていないんです。
- D. データは全て残しています。ですが、どう見たらいいのか困っています。
- E. 重要な数値は毎日確認しているけど、それを見て実際どうのようにしたらいいのかわからなくて……。
- F. うちは担当者の実務経験にまかせているよ。データよりも当てにしているから。
- G. データ? 分析? いやとにかく、できることをがんばればいいんですよ。
データ分析は、さまざまなシーンでビジネス効率を上げることに役立ちます。
我々の体験でも、さまざまな業種、さまざまな職域において、効果の大小こそあれ、役に立つことが多いです。
しかしながら、上記のように、実際には企業内での定着に向けて、課題が多いという実情があります。
上記の言葉の背景にあるものを、分析者の視点から考えてみると
- A’. データ分析、特に機械学習などを、人間にわからない何かが見つかる魔法と勘違いしている。
- B’. データ分析が、複雑な数値解析による現象解説のみになっている。
- C’. データは保存しているが、分析に作業時間や人員などがさけない。
- D’. データは保存しているが、分析ノウハウがない。
- E’. 売上などの重要な数値では現状把握はできているが、その数値から今後具体的にどう行動したほうがよいかわからない。
- F’. データ分析と実務経験は補完関係で相乗効果があることを知らない。
- G’. ただがんばる業務を、より効果的に、ただがんばる業務にできることを知らない。
おおむね、このようなところに落ちつきます。
一般的に、何かを成功させるためには、知る、わかる、できるようになる、成功させることができる、という1つ1つに大きな障壁のある階層があります。
上記のそれぞれ悩みをみると、知らない、わからない、できない、うまく達成できない、と階層が異なるもののデータ分析がビジネスでほんとうに達成可能なことの大枠を知らない。
つまり、そのような情報が少ないということに帰結しそうです。
そこで我々は、この本を通し、実際のビジネスのなかで「データ分析」を行なうことで、何ができるのか、どういうふうに役に立たせることができるのか、を示していきます。
具体的に想定する読者ですが
- ビジネスのデータ分析に関心がある人
- 実際にビジネスでデータ分析を行なっている人
と大きく2つにわけ、それぞれを念頭に執筆しました。

- 1章
- ビジネスのデータ分析にたずさわるデータ・サイエンティストの実態を紹介していきます。
- 2章
- どのようなビジネスにでもあてはまる、汎用性の高いデータ分析のフレームワークを紹介します。
- 3〜6章
- データ分析に関心のある人向けにデータ分析の基礎を説明しています。
- 基礎となる部分ですので、実際このままの形でビジネスに使えるチャンスは少ないのですが、なるべく実務にあわせる形で、ビジネスのデータ分析にまつわる考え方や、実際のやりとりといった業務の説明をおこないました。
- 7〜10章
- ソーシャルゲーム事業で分析業務を行っているかた、あるいはIT業界、さらには他の業界において分析業務をおっている方を対象に、データ分析の応用事例を紹介しました。
- この本のオリジナリティがでるよう「なるべく既存のデータ分析の書籍にはないような分析」かつ「我々が実際に行なっている分析」というなかから4つほどのケースを紹介しました。
データ分析について解説した類書では、書籍の内容にあわせ都合よく用意されたデータを分析していきます。
しかし多くのみなさんはそれらの説明が実務には応用しにくかったという経験はないでしょうか?
この本では、それぞれのケースのなかで最初からきれいではない、いくつかの前処理が必要なデータを用意しました。
このようなデータに対して統計解析の道具をどのように活用していくのかについて、その詳細が明らかになるように構成を工夫しました。
kmeansで楽できる(かもしれない)パッケージを作った
k-means法は、非階層的クラスタリングの代表的な手法ですごく便利ですが、使って行く上で、以下の2つが問題になってきます。
- 初期値がランダムなので、結果がぶれる
- 最適なクラスタ数が分からない
この2つの弱点に対して拡張版や手法が提案されていますが、すごくシンプルな方法で解決するパッケージを作ってみました。
その名もykmeansパッケージ・・・!
- http://cran.r-project.org/web/packages/ykmeans/index.html
- ※改良とか拡張とかしてるわけではないので、kmeans2とか付けるのは自重した
このパッケージは、上記の二つの問題に対して、以下のアプローチで対応しています。
N回実行して一番多く分類されたクラスタを採用する
例えば、あるデータで100回実行して、そのクラスタの平均値をプロットすると、↓のようにクラスタの中心が結構ぶれます。
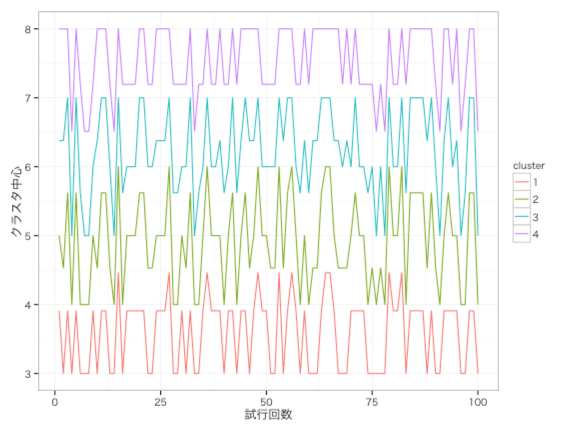
クラスタの中心がずれると、当然分類されるクラスタが変わってしまうデータが出てきます。
なので、1回だけの実行では中々不安になってきます。
そこで、このパッケージでは、
「とりあえず100回くらい実行すれば安定するだろう」
という仮定のもとに、100回実行して、一番多く分類されたクラスタを採用しています。
(※回数は指定出来ます)
任意の変数のクラスタ内分散の平均値が小さくなるクラスタ数を採用する
自分がクラスタリングを使うときは、目的にもよりますが、ある程度クラスタ数の範囲は事前に決めています。
多すぎると解釈や説明がつらくなってくるので、3〜6、多くて10くらいに設定するのが多いです。
また、「クラスタリングして終わり」ではなく、各クラスタのKPIを比較するなど別の分析があります。
なので、クラスタ内で、見ようと思っているKPIが出来るだけ近い方が都合が良いです。
そこで、このパッケージでは、
「見ようと思っている変数が、クラスタ内でなるべく散らばらないクラスタ数」
を採用しています。
使い方
- ykmeans (x, variable.names, target.name, k.list, n)
| x | データフレーム |
| variable.names | クラスタリングの時の使う説明変数名 |
| target.name | クラスタ間で比較しようと思っている変数名 |
| k.list | クラスタ数候補 |
| n | 試行回数 |
実行例
- 使うデータ
library(ykmeans) head(actData)
## y x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 ## 1 17030 7 3 4 3 3 3 3 2 3 3 1 2 3 2 2 2 2 ## 2 1360 5 3 4 4 2 4 3 0 4 2 2 2 2 1 2 2 1 ## 3 1360 7 4 3 4 2 4 3 3 2 3 2 2 2 2 2 2 1 ## 4 100 5 2 3 2 3 1 2 3 2 1 2 1 1 2 1 0 1 ## 5 320 4 3 3 2 3 1 2 2 1 1 2 2 1 1 2 1 0 ## 6 2820 7 4 3 4 3 4 3 3 2 3 3 1 2 2 2 1 1
- ykmeans関数の実行
ykm <- ykmeans(actData, paste0("x", 1:17), "y", 3:6) table(ykm$cluster)
## ## 1 2 3 4 5 ## 140 92 16 148 104
-
- このデータでは、3〜6個のクラスタ数を試して「5」が採用されています。
R CMD checkでno visible binding for global variable 'hoge'
久しぶりにCRANにアップしようと思ったら、R CMD checkで以下のようなのが出てきたのでメモ。
* checking R code for possible problems ... NOTE [関数名]: no visible binding for global variable '[変数名]' ...
注意されてる変数を関数内で初期化すればオッケーなのだが、
plyrとかで使う変数に対しても上記のメッセージが出てしまう。
例えば、関数内で作ったデータフレームを使って、
res <- ddply(data, .(id), summarize, avg=mean(a))
というコードを書いてると、
* checking R code for possible problems ... NOTE [関数名]: no visible binding for global variable 'id' [関数名]: no visible binding for global variable 'a'
って出てしまう。
少し気持ち悪いけど、これも初期化してしまえば、とりあえずメッセージは出なくなる。
id <- NULL a <- NULL; res <- ddply(data, .(id), summarize, avg=mean(a))
データサイエンティスト養成読本を執筆しました&Data Scientist Casual Talk in 白金台で発表してきました
データサイエンティスト養成読本を執筆しました
かなり遅い報告となってしまいましたが、データサイエンティスト養成読本という本を執筆しました!
![データサイエンティスト養成読本 [ビッグデータ時代のビジネスを支えるデータ分析力が身につく! ] (Software Design plus)](https://images-fe.ssl-images-amazon.com/images/I/51jDJwFEw8L._SL160_.jpg "データサイエンティスト養成読本 [ビッグデータ時代のビジネスを支えるデータ分析力が身につく! ] (Software Design plus)")
データサイエンティスト養成読本 [ビッグデータ時代のビジネスを支えるデータ分析力が身につく! ] (Software Design plus)
- 作者: 佐藤洋行,原田博植,下田倫大,大成弘子,奥野晃裕,中川帝人,橋本武彦,里洋平,和田計也,早川敦士,倉橋一成
- 出版社/メーカー: 技術評論社
- 発売日: 2013/08/08
- メディア: 大型本
- この商品を含むブログ (13件) を見る
自分の担当パートは、以下の2つです。
- 特集1の第1章「Rで統計解析をはじめよう」
- 特集2の第1章「Rによるマーケティング分析」
Rで統計解析をはじめよう
- 目次
- Rの導入
- データ把握
- 多変量解析: 予測
- 多変量解析: 分類
- 機械学習
このパートでは、Rの導入からデータの把握、統計解析の実行方法をなるべく網羅的になるように意識して書きました。
参考までに、内容を検討していた時に作った表を載せておきます。
太字になっているところが、本で扱った項目です。

Data Scientist Casual Talk in 白金台
9/6に、Data Scientist Casual Talk in 白金台というイベントで発表してきました。

- 発表資料
このイベントは、データサイエンティスト養成読本が出版されたことを記念にしたイベントで
執筆者が、執筆内容にそった形でカジュアルに講演するといったものでした。
皆さん内容がとても濃く、カジュアルとは一体なんだったのか?という状態でしたが、とても勉強になりました。
また、その後の懇親会でもいろんな人と意見を交わす事ができ、とても良い時間を過ごす事が出来ました。
参考
- http://www.amazon.co.jp/dp/4774158968
- データサイエンティスト養成読本 [ビッグデータ時代のビジネスを支えるデータ分析力が身につく!]:書籍案内|技術評論社
- http://codeiq.hatenablog.com/entry/2013/07/25/120000
- 『データサイエンティスト養成読本』はゼロからデータサイエンティストを目指す人なら絶対に読むべき一冊 - 六本木で働くデータサイエンティストのブログ
- 「データサイエンティスト養成読本」を読んだ - isseium's blog
- 「DataScientist Casual Talk in 白金台」というイベントを開催します - adtech周辺に興味がある人の四方山話
- http://www.zusaar.com/event/1010003
- ドリコムの分析環境とデータサイエンス活用事例
- http://www.zusaar.com/event/1010003
DeNAを退職しました
2011年5月に入社して、2年間ほど勤めたDeNAを本日(6/30)付けで退職しました。
DeNAでの2年間は、2年間とは思えない程濃い時間で、本当に様々な経験をする事が出来ました。
入社して最初は、データマイニング部という部署に配属され、他部門で解決出来ないような難易度の高い課題に対して、各種方法論を使って解を出すといった事をやっていました。
まだデータが整備されていない状態の中で、求められているスピード感&クオリティが高く、中々苦労したのを覚えています。
基本的な統計モデルの適用だったり、他の業界で使われているような応用的な手法の適用、あるいは新しいモデルを作ったりなど、かなりチャレンジングな事をさせてもらいました。
データマイニング部の時に作ったモデルの一つに、TVCMの効果測定モデルがあったのですが、そのモデルを運用してもっと深い分析をしたいというお話があり、出向という形でマーケティングの部署にJOINしました。(その後継続し今年の4月に正式に配属)
マーケティングの現場に入って、外からは分からなかった現場の温度感や、価値観、スピード感などを体感する事ができ、これまでの自分の知っているものとのギャップを実感しました。
エンジニアとマーケってかなり遠い存在なんだなーと改めて思い、この両方を深く経験出来たのはとても運が良かったなと思っています。
エンジニアとしては、前職のようなサービスの開発などはやりませんでしたが、PigやHiveを使った集計バッチやRを使った解析スクリプトの開発、分析用サーバの運用などを担当していました。
あと、地味に分析チーム内のgithubを使った開発体制の構築なんてことも推進したり、PigやHiveだけでなく、ShellやPerlなど技術関連全般のサポート等もやってました。
他にも、プラットフォーム周りの企画や分析、新規サービス周りの分析も担当させてもらい、本当に幅広い領域に触れる事ができました。
もっともっと書きたい事が沢山あるのですが、書き出すとキリがないのでここら辺にしておきます。
旧データマイニング部の皆さん、旧PF分析部の皆さん、マーケティング本部の皆さん、SG分析の皆さん、本当にありがとうございました!
転職のきっかけですが、昨今のデータサイエンティストブームからか、いくつかお誘いがあり、
いろいろ話してみた結果、今よりも自分の持っているスキルや経験をフルに活かせそうな環境と出会ったからです。
ホント急ですが、明日から新しい会社になります。
今後もよろしくお願い致します!
第31回Tokyo.Rを開催しました
第31回Tokyo.Rを開催しました。
※ 資料がまだのものは、公開され次第追記します!
前半(初心者セッション)
後半
LT (5分)
R で自然順ソートを実装してみた (@kos59125)
第30回TokyoRを開催しました
遅くなりましたが、4/20に第30回TokyoRを開催しました。
内容に関しては、CodeIQさんのご協力でU-NOTEに素晴らしいまとめ記事を作成して頂いたので、そちらをご確認下さい。
次回は6/1に開催します。
興味のある方は是非ご参加下さい!